반응형

1. 모바일 HTML 태그를 살펴보자
제목이 a태그에 속해있다

2. URL을 살펴보자
URL을 보면 검색어가 쿼리스트링 형태로 나타나있다.

이 URL을 그대로 가져와 복붙하면 다음처럼 아스키코드로 나타난다.

검색어는 query= 문 뒤에 나오며 아스키 코드로 나타난다는 점에 주목하자.
query값에 search 변수를 삽입하여
입력한 검색어에 해당되는 데이터를 불러오도록 만들자.
여기서!
URL은 아스키코드 형태로 나타나야하므로
아스키코드로 변환시켜주는 quote_plus를 활용하여
quote_plus(search) 를 입력하자.

3. 크롤링 시작하기
html 변수 = 링크를 읽어들인다.
soup 변수 = html태그를 저장 html 변수에서 html만을 저장한다.
total 변수 = 클래스명 api_txt_lines 과 클래스명 total_tit로 된 모든 태그를 가져온다.
맛보기1
첫번째 인덱스만 출력해보자.

맛보기2
반복문에 text, attrs를 사용하여 텍스트와 링크만을 뽑아온다.

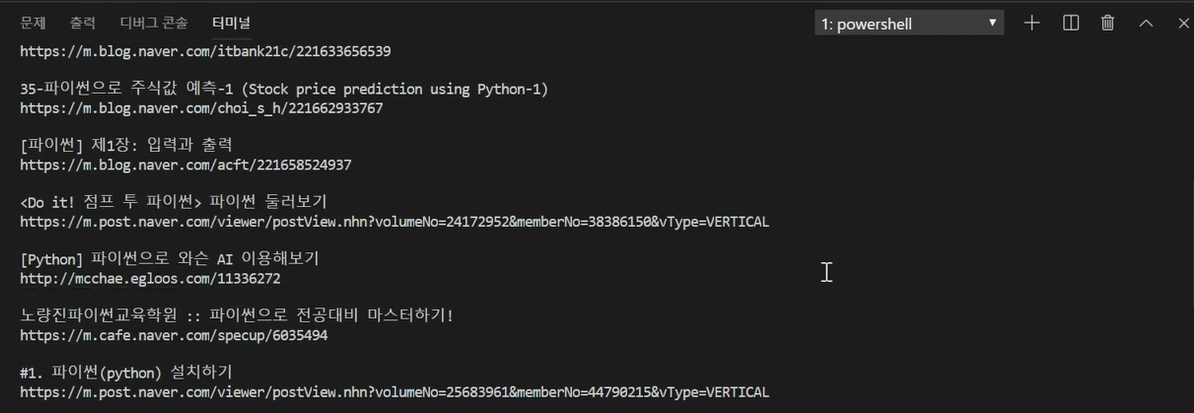
정상적으로 출력된다면 다음 과정을 진행하자.
맛보기3
이중리스트를 사용하여
한 리스트에 텍스트, 링크 1개씩 저장하자.
즉, [[제목1,링크1],[제목2,링크2], ...] 구조로 저장된다.
첫번째 인덱스만 출력해보자

출력 결과

4. csv로 저장하기

반응형
'○ 크롤링, 자동화 > BeautifulSoup' 카테고리의 다른 글
| datetime 모듈로 날짜/시간 처리하기 (0) | 2021.05.15 |
|---|---|
| [문제해결] csv 파일의 한글이 깨진다면? (csv 포맷 변경, 통일시키는 방법) (0) | 2021.05.04 |
| 크롤링 후 불필요한 문자들, 특수문자들 제거하기 (0) | 2021.02.01 |
| 2차원 리스트를 1차원 리스트로 바꾸자 (0) | 2021.02.01 |
| [잔재미코딩] [오류/해결] ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end (0) | 2021.02.01 |

