반응형
크롤링 : 웹에서 허용된 링크를 따라가면서 마주잡이로 끌어옴
스크래핑 : 필요한 것만 뽑는 것
HTML : 집의 골격
CSS : 인테리어, 예쁘게
JS : 내부 생활, 생동감있게
웹 스크래핑을 보면서 반드시 HTML의 골격, 구조를 이해해야만 한다.
HTML에 대해 알아보자
Hyper Text Markup Language



X Path에 대해 알아보자
unique한 값으로 간편하게 찾는 경로를 의미함
1. 전체 경로를 써서 찾는 경우
왜냐? 비슷한 태그, 엘리먼트 중 어떤 것을 지칭하는지 명확하게 하기 위함

위처럼 특정하기 위해서 길게 쓰는 경우도 있지만
2. 클래스,id 속성 등의 unique한 특징으로 찾는 경우
unique한 값으로 줄여서 쓰는 경우도 있다.
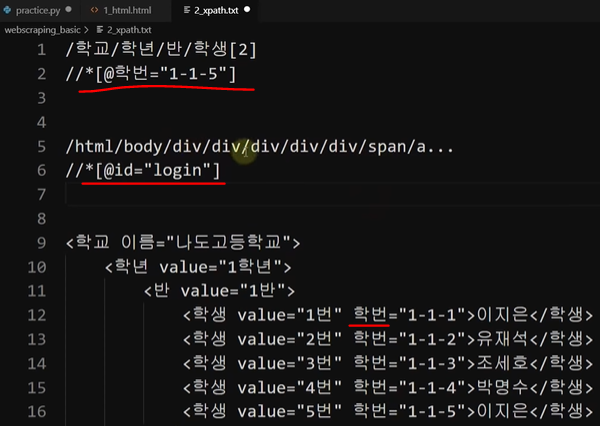
일반적으로는 id, class속성으로 특징으로 간편하게 줄일 수 있다. 이것이 바로 X Path
Request
원하는 페이지로 접속한 뒤 정상적으로 정보를 받았는지 확인하고 파일로 만들어보자.
터미널창
pip install requests
import requests
res = requests.get("")
print("응답코드 :", res.status_code) # 200이면 정상, 올바르게 url을 가져왔음
res.raise_for_status() #오류가 있으면 바로 프로그램을 끝냄
print("웹 스크래핑을 진행합니다.")위 코드를 줄이면 다음과 같이 된다
import requests
res = requests.get("http://naver.com")
res.raise_for_status() #오류가 있으면 바로 프로그램을 끝내고 없으면 스크래핑 진행
추가로 가져온 코드를 html 파일로 만들어보자
import requests
res = requests.get("http://google.com")
res.raise_for_status() # 오류가 있으면 바로 프로그램을 끝내고 없으면 스크래핑 진행
# 위 url에 수집된 코드를 출력해보자
print(len(res.text))
print(res.text)
# 수집된 코드(res.text)를 html파일로 저장해보자
with open("mygoogle.html", "w", encoding="utf-8") as f :
f.write(res.text)정규식 Regular Expression
줄여서 re
정해진 형태의 식
주민번호/이메일 형태를 생각해보면 좋다
int 형태의 주민번호 ****** - *******
str 형태의 이메일 abcd@naver.com


IF 조건문으로 만들어보자

조건문을 함수로 만들자



55:00
반응형
'○ 크롤링, 자동화 > BeautifulSoup' 카테고리의 다른 글
| [나도코딩] 파이썬 코딩 무료 강의 (활용편3) - 웹 크롤링? 웹 스크래핑! 3 : attrs, find, class, sibling, siblings (0) | 2020.08.28 |
|---|---|
| [나도코딩] 파이썬 코딩 무료 강의 (활용편3) - 웹 크롤링? 웹 스크래핑! 2 : User Agent (0) | 2020.08.27 |
| [잔재미코딩] 7. 한빛미디어 페이지 실전 크롤링 쿠키와 세션 찾기 (0) | 2020.03.12 |
| [잔재미코딩] 6. 로그인이 필요한 페이지 크롤링하기 (0) | 2020.03.10 |
| [잔재미코딩] 4. 게시판 크롤링, 반복문, 엑셀파일 정리 (0) | 2020.03.04 |



