파이썬의 대표 분석 라이브러리 pandas
수식을 통해 시각화하는 도구
panner data system의 약자
panner data = 행열, 엑셀유사 데이터를 다루는 것
엑셀과 유사함
엑셀로도데이터분석가능하지만이를이용하는이유?
1. 엑셀로는 힘든 대용량의 데이터를 판다스는 분석할 수 있기 때문
2. 주피터노트북에 소스코드작성시 파일만 로드하면 기존소스 재사용 가능
3. 월,주별 반복 작업은주피터노트북에 작성 후 사용가능
추천하는 학습문서 2가지
1. 10minutes to pandas문서를따라해볼것을추천(따라해보는데2,3시간소요되지만책한권 읽은것과 유소한효과)
2. 2장의 문서로 이뤄진pandas cheat sheet 문서 추천. 이 문서에있는것만익혀도판다스를사용할때무리가없음
판다스 불러오기
import pandas as pd
dataframe 공식문서불러오기_하단처럼 2가지 방법이 있다
1. pd.DataFrame?
2. pd.DataFrame(Shift+tab+tab)

pandas cheat sheet문서로 학습해보자

DataFrame

Series


Subset

행을 기준으로 값가져오기


칼럼을 기준으로 값가져오기

2가지 방법
1. 대괄호를 한번해서 가져오는 Series형태_1개 칼럼
2. 대괄호를 두번해서 가져오는 DataFrame형태_2개 이상 칼럼, 리스트형태로 감싸줄 것

Summarize Data

데이터 프레임의 형태를 다음과 같이 바꿔서 진행해보자


Reshaping_정렬,드랍



axis에 대한 설명을 읽어보자

Group Data

pivot vs pivot table

pivot : 행에 있는 데이터를 열로 보낼 수 있음, 데이터 요약 가능, 형태만 바꿈
pivot table : 값을 연산할 수 있음
pivot_table을 하기에 앞서 Groupby부터 해보자
Groupby
어떤 컬럼값을 기준으로 그룹바이해서평균값 등등 수치계산가능하다
1) "a" 컬럼값을 기준으로 Groupby하여 "b"의 컬럼값 평균값 구하기
df.groupby(["a"])["b"].mean()


pivot_table
2) pivot_table로 평균값 구하기


입력해보자
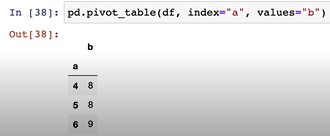
pd.pivot_table(df, index="a")


칼럼 a를 그룹화하면 기본적으로 평균값이 적용된다.
칼럼 a의 요소는 4,5,6,4
4가 2번 등장한다.

4가 등장하는 1,4 인덱스의 b의 값은 7,9이다.
7,9의 평균값은 (7+9)/2 = 8 이다.
하단처럼 values="b"를 추가해도 동일하게 나온다.
총합구하기
앞에선 기본적으로 평균값을 구하도록했지만
aggfunc을 sum으로 바꿔 총합을 출력한다.

Plotting_데이터시각화
데이터를 가지고 다양한 시각화를 해보실 수 있습니다.

df.까지입력후 tab키를 누르면 여러 기능이나온다
1) 꺾은선 그래프 그리기

2) 막대그래프 그리기

3) 밀도함수 그리기

'○ 인공지능, 분석 > 20.07 edwith_DS with Python' 카테고리의 다른 글
| 2.3 파일경로설정방법, jupyter 파일경로변경하기, "지정된 파일을 찾을 수 없습니다" (0) | 2020.07.06 |
|---|
