리스트
| len(a) | 리스트 길이(자료 개수)를 구한다 | a = [] len(a) |
| append(x) | 자료 x를 리스트의 맨 뒤에 추가 | |
| insert(i,x) | 리스트의 i번 위치에 x를 추가 | a.insert(0,5) # 0번 인덱스에 5추가 |
| pop(i) | i번 위치에 있는 자료를 리스트에서 빼내면서 그 값을 함수의 결과값으로 돌림만약 i 미지정시 맨 마지막 값을 뺌 | a.pop() a.pop(0) # 0번 인덱스 출력되고 빠짐 |
| clear() | 리스트의 모든 자료 지움 | a.clear() # 빈리스트됨 |
| x in a | 어떤 자료 x가 리스트 a안에 있는지 확인. (x not in a는 반대) | a = [1,2,3] 2 in a 3 in a 4 in a |
총합을 구하는 알고리즘
def sum(n) :
return n*(n+1) // 2
제곱의 합을 구하는 알고리즘
def sum(n) :
return n*(n+1)*(2*n+1) // 6최댓값 구하는 알고리즘
n = [17,92,18,33,58,7,33,42]
def comparison(n) :
len_n = len(n) # list는 int가 아니므로 길이를 나타내려면 len을 써야한다.
max_n = n[0]
for i in range(1,len_n) :
if n[i] > max_n :
max_n = n[i]
return max_n, i
print(comparison(n))
n = [17,92,18,33,58,7,33,42]
def comparison(n) :
len_n = len(n) # list는 int가 아니므로 길이를 나타내려면 len을 써야한다.
max_n = n[0]
for i in range(1,len_n) :
if n[i] > max_n :
max_n = n[i]
return max_n, i
print(comparison(n))최댓값의 위치 구하기
n = [17,92,18,33,58,7,33,42]
def comparison(n) :
len_n = len(n) # list는 int가 아니므로 길이를 나타내려면 len을 써야한다.
max_n = 0
for i in range(1,len_n) :
if n[i] > n[max_n] :
max_n = i
return max_n
print(comparison(n))
n = [17,92,18,33,58,7,33,42]
def comparison(n) :
len_n = len(n) # list는 int가 아니므로 길이를 나타내려면 len을 써야한다.
max_n = 0
for i in range(1,len_n) :
if n[i] > n[max_n] :
max_n = i
return max_n
print(comparison(n))
집합
집합은
같은 자료가 중복되어 들어가지 않고,
자료의 순서도 의미가 없다.
자동으로 순서가 정렬된다
| len(s) | 집합 길이 구함 | len({1,2,3}) |
| add(x) | 집합 자료 x를 추가 | |
| discard(x) | 집합에 자로x가 있다면 삭제함 없으면 변화없음 |
s = {1,2,3} s.discard(2) |
| claear() | 집합 모든 자료 지움 | |
| x in s | 자료x가 집합s에 들어있는지 확인 | s = {1,2,3} 5 in s 5 not in s |
동명이인을 찾는 알고리즘
# 두 번이상 나온이름 찾기
# 입력 : 이름이 n개 들어있는 리스트
# 출력 : 이름 n개 중 반복되는 이름의 집합
def find_same_name(a) :
len_a = len(a)
same_name = set()
# 빠짐없이 비교하되 중복비교하지 않도록 작성
# 내부값끼리 비교하는 것이므로 2중 for문
for i in range(0,len_a-1) : # 모든 인덱스 비교
for j in range(i+1,len_a) : # 비교안된 인덱스
if a[i] == a[j] : # 인덱스의 값이 동일하다면
same_name.add(a[i])
return same_name
name = ["T","J","M","T"]
print(find_same_name(name))
# 두 번이상 나온이름 찾기
# 입력 : 이름이 n개 들어있는 리스트
# 출력 : 이름 n개 중 반복되는 이름의 집합
def find_same_name(a) :
len_a = len(a)
same_name = set()
# 빠짐없이 비교하되 중복비교하지 않도록 작성
# 내부값끼리 비교하는 것이므로 2중 for문
for i in range(0,len_a-1) : # 모든 인덱스 비교
for j in range(i+1,len_a) : # 비교안된 인덱스
if a[i] == a[j] : # 인덱스의 값이 동일하다면
same_name.add(a[i])
return same_name
name = ["T","J","M","T"]
print(find_same_name(name))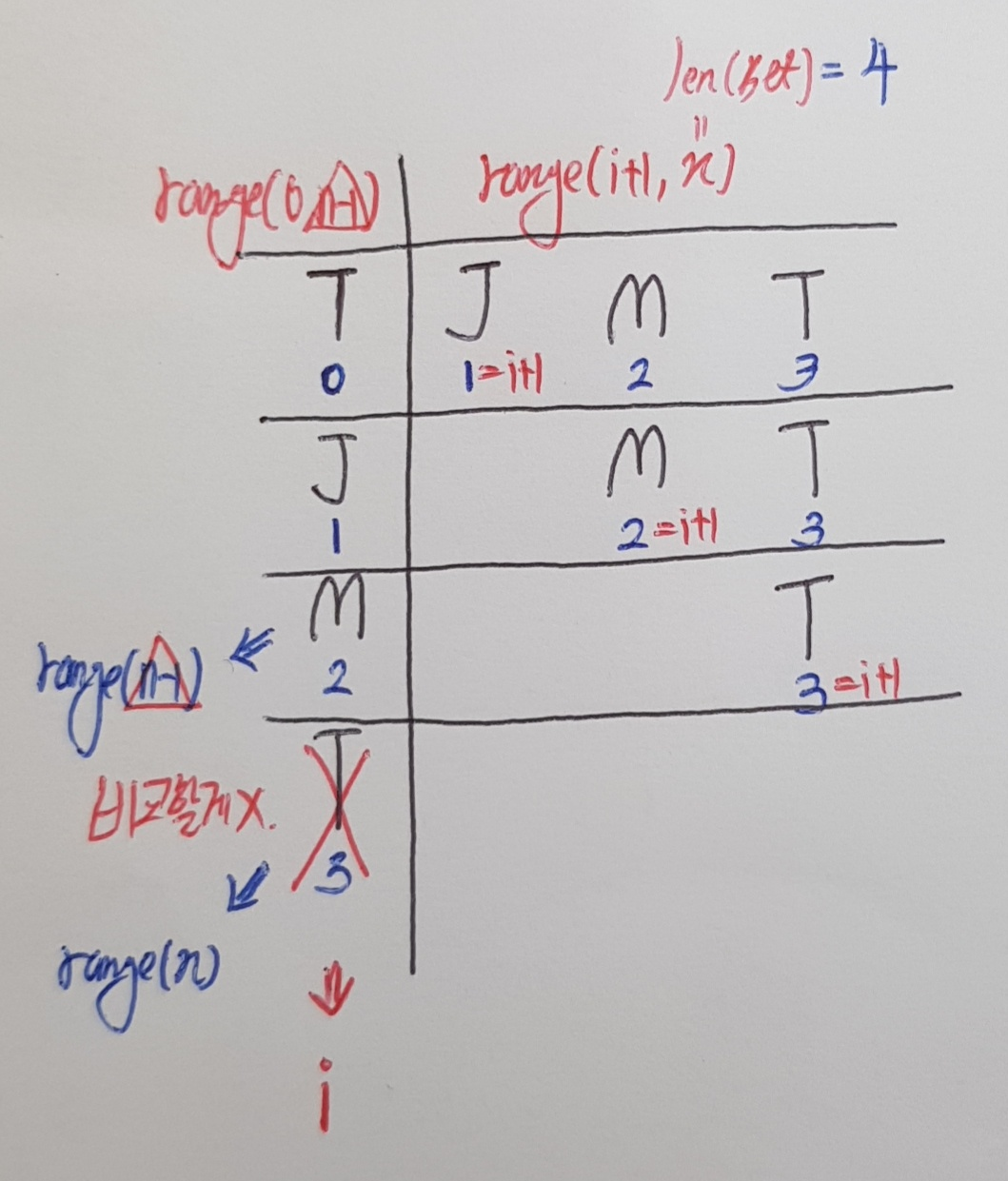
'○ 알고리즘, 자료구조 > 2019 알고리즘' 카테고리의 다른 글
| 순차탐색 (0) | 2019.09.26 |
|---|---|
| 최대공약수 GCD 알고리즘. 유클리드. (0) | 2019.09.25 |
| 함수 (0) | 2019.09.24 |
| python 딕셔너리 (0) | 2019.09.24 |
| python switch (0) | 2019.09.24 |