○ 인공지능, 분석/21.07 코드잇_DS과정
3-5. DataFrame 이론 및 실전 | indexing, 칼럼 출력, 2개 파일 통합
0ver-grow
2021. 9. 10. 10:58
반응형
indexing
import pandas as pd
df = pd.read_csv('data/iphone.csv', index_col=0)
특정 row, column 출력하기
행을 출력하려면 loc를 사용한다.
행과 열을 출력할때도 loc를 사용
열만 출력할 때는 loc없어도 됨. (단, 연속된 column을 출력할 때는 loc 사용)
iphone 8(행)의 메모리(열)를 출력해보자
df.loc['iPhone 8','메모리'] # 행, 열을 지정iPhone X의 전체 행을 출력해보자
df.loc['iPhone 8'] # 행 인덱스 네임만 입력'출시일'을 출력해보자. (1가지 칼럼만 출력하기)
df.loc[ : , '출시일'] # 칼럼 네임만 입력df['출시일']출시일, 메모리를 출력해보자. (2가지 칼럼 출력하기)
df[['출시일','메모리']] # 칼럼 네임만 입력💥 2개의 csv파일을 하나의 DataFrame으로 만들기
samsong DataFrame 형태 (hyundee도 동일 형태)
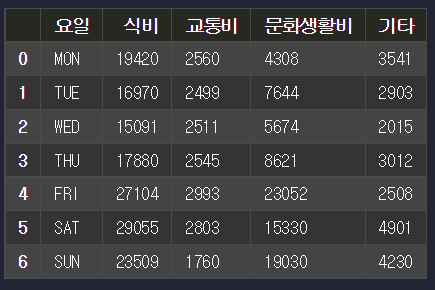
이 2가지 파일을 다음처럼 만들어볼 것

하단 코드는 힌트!
names = ['dongwook', 'sineui', 'ikjoong', 'yoonsoo']
english_scores = [50, 89, 68, 88]
math_scores = [86, 31, 91, 75]
dict1 = {
'name': names,
'english_score': english_scores,
'math_score': math_scores
}
기본 코드
import pandas as pd
samsong_df = pd.read_csv('data/samsong.csv')
hyundee_df = pd.read_csv('data/hyundee.csv')문제풀이
이 중에서 우리가 활용하고 싶은 데이터는
'요일', samsong_df의 '문화생활비', hyundee_df의 '문화생활비' 입니다.
samsong_df['요일']
samsong_df['문화생활비']
hyundee_df['문화생활비']
이제 딕셔너리를 활용봅시다. (딕셔너리로 DataFrame 만드는 방법 참고)
딕셔너리를 사용해야 결합 가능!
우리가 원하는 세 개의 column은 'day', 'samsong', 'hyundee' 입니다.
그럼 사전을 이렇게 만들 수 있겠네요.
{'day': samsong_df['요일'],
'samsong': samsong_df['문화생활비'],
'hyundee': hyundee_df['문화생활비']}최종코드
import pandas as pd
samsong_df = pd.read_csv('data/samsong.csv')
hyundee_df = pd.read_csv('data/hyundee.csv')
combined_df = pd.DataFrame({
'day': samsong_df['요일'],
'samsong': samsong_df['문화생활비'],
'hyundee': hyundee_df['문화생활비']
})
combined_df
반응형
